Cómo implementar un sistema de monitoreo de tiempos de respuesta en VMs
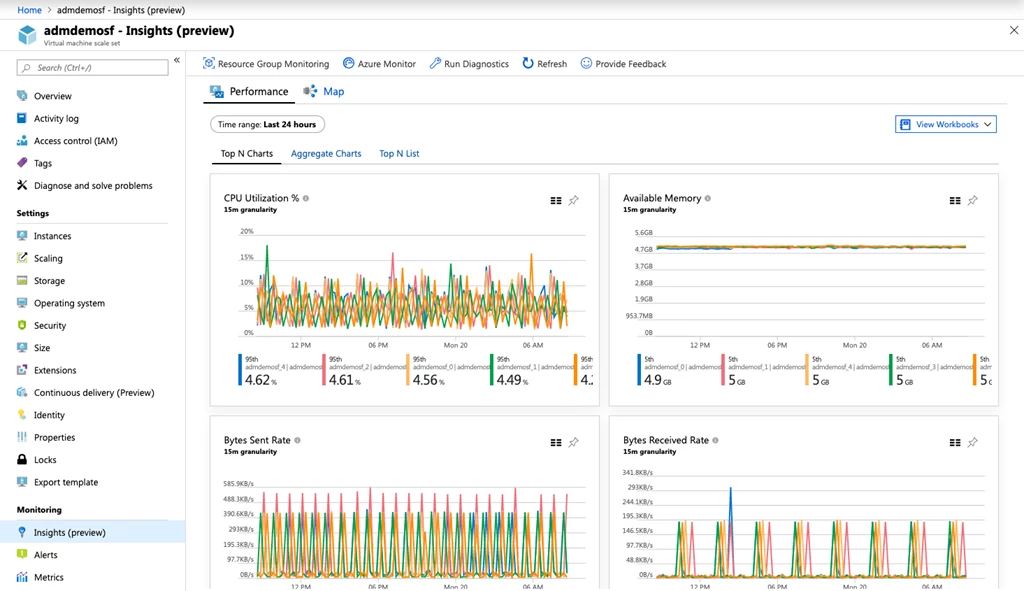
En la era de la tecnología, las empresas dependen cada vez más de la infraestructura de virtualización para alojar sus aplicaciones y servicios. La virtualización permite a las organizaciones ejecutar múltiples sistemas operativos y aplicaciones en una sola máquina física, lo que ahorra costos y mejora la eficiencia. Sin embargo, a medida que el número de máquinas virtuales (VMs) aumenta, el monitoreo de los tiempos de respuesta se vuelve esencial para garantizar un rendimiento óptimo. En este artículo, exploraremos cómo implementar un sistema de monitoreo de tiempos de respuesta en VMs y cómo puede ayudar a las empresas a detectar y solucionar problemas de rendimiento de manera rápida y efectiva.
Antes de sumergirnos en los detalles de la implementación, es importante comprender qué son los tiempos de respuesta y por qué son tan críticos en el entorno de las VMs. Los tiempos de respuesta se refieren al tiempo necesario para que una solicitud se complete desde el momento en que se envía hasta el momento en que se recibe la respuesta. En el caso de las VMs, esto incluye el tiempo necesario para que el hipervisor procese la solicitud, así como el tiempo necesario para que la VM propiamente dicha realice la tarea solicitada y envíe una respuesta de vuelta al cliente. Esencialmente, los tiempos de respuesta son un indicador clave del rendimiento de las aplicaciones y servicios alojados en las VMs.
Beneficios del monitoreo de tiempos de respuesta en VMs
Antes de explorar cómo implementar un sistema de monitoreo de tiempos de respuesta en VMs, es importante comprender los beneficios que esto puede brindar a las empresas. El monitoreo de tiempos de respuesta en VMs ayuda a las organizaciones a:
- Identificar cuellos de botella de rendimiento: Al monitorear los tiempos de respuesta de las VMs, las empresas pueden identificar rápidamente cualquier cuello de botella que pueda estar impactando el rendimiento de sus aplicaciones. Esto les permite tomar medidas correctivas y optimizar el rendimiento de sus sistemas.
- Detectar problemas de red: Los tiempos de respuesta lentos o incoherentes también pueden ser indicativos de problemas de red. El monitoreo de tiempos de respuesta en VMs puede ayudar a identificar problemas como congestión de red, latencia excesiva o pérdida de paquetes.
- Mejorar la experiencia del usuario: Los tiempos de respuesta rápidos y consistentes son esenciales para brindar una buena experiencia al usuario. Al monitorear los tiempos de respuesta de las VMs, las empresas pueden asegurarse de que sus aplicaciones y servicios se entreguen de manera rápida y eficiente.
- Planificar la capacidad de forma efectiva: El monitoreo de tiempos de respuesta en VMs también puede ayudar a las organizaciones a planificar las necesidades de capacidad futuras. Al observar las tendencias de los tiempos de respuesta, las empresas pueden identificar cuándo necesitan agregar más recursos y cuándo están subutilizando sus VMs.
Implementación del sistema de monitoreo de tiempos de respuesta en VMs
Ahora que comprendemos los beneficios del monitoreo de tiempos de respuesta en VMs, es hora de explorar cómo implementar este sistema en la infraestructura virtualizada. Hay varias herramientas y enfoques disponibles, pero en este artículo nos centraremos en una solución basada en software llamada 'Prometheus'.
Leer También:Tendencias actuales en monitoreo de máquinas virtualesPaso 1: Instalación y configuración de Prometheus
El primer paso es instalar y configurar Prometheus en su entorno de VM. Prometheus es una herramienta de monitoreo y alerta de código abierto que se enfoca en el monitoreo de sistemas y servicios de TI. Puede recopilar y almacenar métricas de diferentes fuentes y proporcionar visualizaciones y alertas en tiempo real. Para comenzar, descargue el último paquete de Prometheus desde el sitio web oficial y siga las instrucciones de instalación y configuración.
Una vez que Prometheus esté instalado, deberá configurarlo para recopilar las métricas de tiempos de respuesta de sus VMs. Esto se puede hacer a través de la configuración del archivo 'prometheus.yml', donde puede especificar los endpoints de sus VMs y las métricas que desea recopilar. Por ejemplo:
scrape_configs:
- job_name: 'vm_metrics'
static_configs:
- targets: ['vm1:9100', 'vm2:9100']
metrics_path: /metrics
params:
module: [http_2xx, http_3xx, http_4xx, http_5xx]
relabel_configs:
- source_labels: [__param_module]
target_label: module
- source_labels: [__address__]
target_label: instance
- target_label: __address__
replacement: prometheus:9090
En este ejemplo, estamos configurando Prometheus para recopilar métricas de dos VMs (vm1 y vm2) a través del puerto 9100. También estamos especificando las métricas que deseamos recopilar (http_2xx, http_3xx, http_4xx, http_5xx). Puede personalizar esta configuración según sus necesidades y la configuración de su entorno.
Paso 2: Exportadores y etiquetas
Una vez que Prometheus esté configurado para recopilar métricas de las VMs, necesitará instalar exportadores en las VMs para exponer las métricas adecuadas. Los exportadores son bibliotecas o servicios que se ejecutan en las VMs y recopilan y exponen métricas en un formato compatible con Prometheus.
Leer También: Cómo optimizar el monitoreo de máquinas virtuales
Cómo optimizar el monitoreo de máquinas virtualesPor ejemplo, puede instalar el exportador 'node_exporter' en sus VMs para recopilar métricas del sistema operativo y las aplicaciones en ejecución. Esto se puede hacer descargando el último paquete de 'node_exporter' desde el sitio web oficial y siguiendo las instrucciones de instalación y configuración.
Además de los exportadores, también puede agregar etiquetas a las métricas para facilitar el filtrado y la segmentación. Las etiquetas son pares clave-valor que se pueden adjuntar a las métricas para agregar información adicional. Por ejemplo, puede agregar una etiqueta 'ambiente' con los valores 'producción' y 'desarrollo' para identificar las VMs que pertenecen a cada ambiente.
Paso 3: Configuración de alertas
Además de recopilar métricas, Prometheus también puede configurarse para enviar alertas en caso de que los tiempos de respuesta superen un umbral predefinido. Esto le permite detectar y solucionar rápidamente cualquier problema de rendimiento en sus VMs.
Para configurar alertas en Prometheus, deberá definir reglas de alerta en el archivo 'prometheus.rules.yml'. Por ejemplo:
Leer También: La importancia de la monitorización en la continuidad del negocio
La importancia de la monitorización en la continuidad del negocio
groups:
- name: VmAlerts
rules:
- alert: HighResponseTime
expr: vm_response_time > 1
for: 5m
labels:
severity: warning
annotations:
summary: "High response time detected"
description: "Response time of VM is {{ $value }} seconds"
En este ejemplo, estamos configurando una regla de alerta que se activará si el tiempo de respuesta de una VM es superior a 1 segundo durante al menos 5 minutos. La alerta se etiquetará como 'advertencia' y se proporcionará un resumen y una descripción para ayudar a los operadores a comprender el problema.
Conclusión
Implementar un sistema de monitoreo de tiempos de respuesta en VMs es esencial para garantizar un rendimiento óptimo de las aplicaciones y servicios virtualizados. El monitoreo de tiempos de respuesta puede ayudar a las empresas a identificar y solucionar problemas de rendimiento de manera rápida y efectiva, mejorar la experiencia del usuario y planificar la capacidad de manera más eficiente. A través de herramientas como Prometheus y el uso de exportadores y etiquetas, las organizaciones pueden recopilar y analizar métricas de tiempos de respuesta y configurar alertas para detectar cualquier anomalía. No subestime la importancia del monitoreo de tiempos de respuesta en su infraestructura de VMs y siga las mejores prácticas para asegurar un rendimiento óptimo de sus sistemas.
Deja una respuesta
Artículos más Leidos: